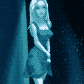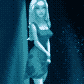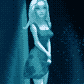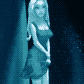Looks like you'll have to reconnect your patreon account from https://satinminions.com/myProfile I think this was caused by a patreon outage a few days ago. I'll go over the code and improve the error handling and logging of this.
On the technical side, this is images from the comic page cropped out and run through cog video, then upscaled and image-to-image filtered in stable diffusion using a LORA and hypernet that I trained on images of the morale officer. (The comic page itself also has backgrounds that are enhanced with stable diffusion - I sketched and shaded a rough background, then filtered them to add greeblies). I then ran it through RIFE to interpolate from 8fps to 16fps.
This took me a couple days of experimenting and messing around, with a large amount of compute time in between. It takes ~10 minutes to render a 6 second clip so it's a matter of figuring out a prompt and parameters, running a batch over night, then cherry picking the best results.
Hand animating this scene would take weeks, but the results and methods aren't really comparable. You're seeing this scene because it worked, where several other scenes did not. While I was generating clips, it was not clear that the walking shot was going to work at all as there were lots of derpy results, and even in the final clip I couldn't use the whole thing. But the final result is very realistic with shading and 3D camera motion that would be very hard to duplicate traditionally. The same with the shot of her walking down the stairs - it looks just like a handheld camera shot and I think you would need to have a motion capture source to duplicate that.
There are lots of things the model just can't do. Like having her walk into the hallway and turn down the stairs - not happening. It has to go forward from the image you provide, so it can't have a can't have a character walk into frame or hit a specific mark. If this model had the 2 keyframe targets that tooncrafter has it would be amazing, but I don't know if that's possible. Also just on some preliminary testing, I don't think it can make the princess from better this way jump up in surprise in the lightning scene.
It favors realistic shading - if you give it a flat shaded character you can get limited animation or lots of distortion. I've had mixed results on some of my characters but it seems to pick up well on this style of the morale officer. The output from cogvideo is very smooth, but it can do some weird things to faces and the overall shading style, thus I ran it through stable diffusion which has it's own problems and adds some flickering.
Re: Jiggle physics, I've gotten some ok results by feeding it photorealistic stable diffusion renders of girls in loose tshirts. Here's some misc results for science: https://satinminions.com/Cog-Misc-Results.html
The model seems to shine at realistic scenes with minimal movement. You get lots of subtle secondary motion and it holds the character's proportions well. I think there might be a hybrid use where you draw a character, generate an animation, then roto over it. Also for backgrounds and establishing shots, you can add rotation and animation to what would otherwise be an ordinary pan. Another case that seems to work with a little fiddling is techno babble displays, like the brain scan and graph stuff that appears on the morale officer's hud. So there are use cases but it's not the end times yet.
Multi-answer, or approval voting, is the superior type of voting system. It avoids the spoiler effect and you can safely vote for third parties without "throwing your vote away"
For the sake of completionism, here is a result from Kling AI image-to-video. It's another web service with the usual problems that come from using someone else's computer.
The motion and consistency is an improvement over previous models. There's distortion in the face but this might be correctable with a style-specific post process.
The main problem is that this animation took multiple *days* to render. The site is just completely overloaded. This would be acceptable if they had a job queue that honestly said "you are number 45000 in line" or whatever, but instead they have a fake progress bar that gets to 99% and stops. This is apparently a persistent problem even for paid accounts.
Right now I think we're getting the worst end of AI, where it's convincing enough on the surface to blow up social media, but not really practical enough for a big improvement in production.
There is a (bright?) future where a single person will be able to make a complete film using these tools. I don't know what it'll be like when there's a thousand or ten thousand new shows released every year but it sounds like we will live in interesting times.
My worry is that the best tools will remain proprietary and lawfare will be used to remove the open source alternatives.
Some people think that the current tech will cap out and never really be useful - I think this is cope. The capabilities are clearly already there, it's just a matter of controlling them.
It is unnerving for sure - especially when I go to deviantArt or rule34 or even google images and the entire page is destroyed with ai garbo. I've said this before but that's why I feel the need to mess with it, because I need to understand the threat and how to use it.
Oh I guess my other big worry is that we'll enter a completely post-fact world and it'll be impossible to find a verifiably real image of anything. Every book will be rewritten and every image repainted, all recently recorded history will be in doubt, etc.
The stability and movement are impressive and it has a good understanding of materials such as the sequins and satin gloves. It tends to favor a photo realistic style, 3D rendered style, or a generic flat anime look depending on how you prompt it. Sometimes it will cut to a completely different scene, like this: https://satinminions.com/LumaLabs-Combat-Mode-Cut.html
We're fast approaching the point where generative video AI can replace stock footage, things like "man using computer" or "drone shot of new york city at night" can be completely convincing. And of course memes where consistency doesn't matter are great. But I don't think the current model architectures will be able to replicate a style or character without specific training.
The current target audience seems to be the zero-skill user, where you only have to provide the bare minimum - because that's what gets the most engagement. As a "professional" though, I would much rather see tools that required more advanced inputs - for instance, input a complete line animation and a single colored frame and it would propagate that coloring through the animation.
This is a result from Krea AI image-to-video. It is implemented as web application where you can upload keyframes and prompts on a timeline. I used these two images as keyframes:
It's eye catching and very smooth (at least in the face), but it does not follow the original keyframes or style very strongly. I think this could be tweaked to get better results, but my "3 minutes" of free trial video generation got used up in 20 seconds, and that doesn't exactly encourage me to purchase more time.
Having a timeline with keyframes is a step in the right direction, but the hard push towards content control and monetization seems premature for something that's not really cut out for professional use.
This is a result from RunwayML Gen2 AI image-to-video. It is implemented as a web service, so it costs money, it can be slow, there is content filtering, and you're at their mercy for data privacy and access.
It generally struggles to maintain a consistent form, with characters often melting into someone else if there is significant animation. It also can't replicate a style, which is why I used the stable diffusion edit of this character as the image prompt, since it is a more generic photorealistic style.
They have announced Gen3, but it is not available to the public yet. From the results they've shown, I'd say it has potential to replace stock video for corporate ads and video essay filler, but it's not quite there yet for animation production.
Pika Labs AI image-to-video does a pretty decent job at realistic smoke, water, rain, fire, that sort of thing. The intent seems to be to create cinemagraphs.
This AI image-to-video from Pika Labs. You provide a single image and a text prompt and roll the dice. It's implemented as an online service via a discord bot so you sometimes have to wait a long time and there is NSFW filtering.
This was one of the only results I managed to get with a coherent movement that didn't morph into something strange. Most of the time you get the windy hair/fabric effect applied to random parts of the image or no animation at all.
Maybe if it could run locally, you could run it hundreds of times and cherry pick good results, but as it is now, it doesn't seem to have any use at all.
This is another result from ToonCrafter, an AI frame interpolator, this time fed with panels from the opening scene of Lighter Chains Volume 5. There's some weird bits of course, but there's a lot of potential here for automating the "boring" parts of an animation where you just need some blocking and idle animations.
As a storyboarding aid, this can also show what amount of limited animation you can get away with - some of the shots work surprisingly well.
I've had some interesting results upscaling the frames from this in stable diffusion, but I want to see if doing some quick fixes to the animations or training a lora on the source panels can help things.
Well prepare to sit wrong because I have tried several image-to-video AIs I'll be posting the results and my thoughts this week.
The goal isn't to make the best finished work right off the bat, but to test the technology and see what it can do - good and bad. Part of learning a new tool.
It's gotten to the point where the sketches are so old that I don't think they're very good, even more so for "the summoner's sex" comic. I guess I like to save the worst content for my patrons.
I found this color version of the character design and the previous sketch ending page that I never posted. It's a little rough but I'm not going to fix anything because it is so old.
Tacking it on as a bonus page to the comic so all of this character is in one place without needing another character tag.
I have avoided SDXL because the results did not seem materially better than SD1.5, it did not have control net, and I would have to re-train my loras/hypernets using some unknown process.
I just tried updating updating everything and downloading the SDXL control net models and it's giving me bad/garbled results. I'm really sick of every update to this thing turning into a research project. I hate that stability AI just teases new stuff forever then eventually releases a pile of broken parts with no instructions and you have to wait another six months for internet randos to put it together while dodging grifters and criminals.
Stability could just put together a product that actually works, release it on steam, charge $50, and make $100M this weekend. Then they wouldn't be in this situation where lawyers come after them for training on whatever data set and they don't have any money to defend themselves so they just cave and gimp their models and hope someone in the community can un-gimp them.
On the other end, we've got trillion dollar corpos all competing to see who can make the most powerful AI that is simultaneously useful enough to be mandatory but crippled enough to never do anything interesting. I can't wait until ChatGPT-4o is forcefully crammed into the next windows update so when I type on my computer something completely random happens and then the synthesized staccato voice of a virtual HR manager chimes in to gaslight me into thinking that's what I wanted.
We've discovered the killer app for AI - and it's telling lies. That's what it's best at, because that's how we train it. The RLHF (reinforcement learning from human feedback) step is not based on truth, it is based on convincing humans that it is telling them the truth. They have to lie convincingly to make it from dev to production. We've actually engineered a nightmare science fiction scenario where AIs are trained to talk their way out of confinement - this is literally a classic AI safety talking point that we've just blown right past without even noticing.
Sorry for the rant, I'm sure there's a button or something I'm missing. I've just gotta post this stuff somewhere before the bots take over.
Forgive the meme. I have spent the last several weeks battling the four horsemen of linux, apache, mysql, and php to merely hold my ground against the inevitable tide of entropy. Although it does seem faster. Enjoy continuing to exist.
In this case I just threw the whole animation through RIFE and made it as smooth as possible. That can make the timing wrong in some parts and also expose flaws in the animation.
For my latest animations, I used it more strategically to only add frames where they're needed and to save time. If you go through "The Offering" frame by frame you'll see some artifacts, but it's mostly hidden in motion. The way her breathing slows down at the end without losing fluidity would have taken much longer without the frame interpolation.
Ultimately I think the best use of the technology is where it disappears, rather than takes center stage like in this piece.
This is the same prompt generated through different models. I fiddled around with prompts and controlnet until I found something good, then generated 9 images with the same prompt but different ControlNet weights to animate from the source image to the transformed image.
Each image takes ~23 seconds to render on my 4090. Then I did 8x frame interpolation with RifeApp and that takes another couple of minutes for each segment.
It will render her chain choker if I prompt it to, but sometimes that has side effects like turning the dress ruffles or sandal straps into chain, and I wanted something consistent for the animation trick.
I tried but the AI just isn't up to it. The X-ray is definitely out, but even without it, stable diffusion has problems with two different people in the same scene, even more problems if they're touching or overlapping. It works best on landscapes and solo pinup poses.
It's just a monochrome palette, that I've tried in various hues over the years. This palette evolved from the one I used in "Entry Level Positions", which was inspired by "Tawawa on Monday"