

Should be working now if you reload.

https://satinminions.com/search?tags=Tentacles
It's rare but it's there.
It's rare but it's there.

This animation actually has 4 (I think) RIFE interpolated frames in it, but you can't even tell where they are. I only used them to change the timing, not to make it ultra smooth and uncanny.

My primary tool is still WAN2GP by DeepBeepMeep, specifically using the Wan2.1 model. It seems to give the best results and is trainable on a 24GB card, so there are lots of loras available and I can make my own for style. I vibe coded a python script to stabilize the colors between frames and one to do rife crossfades between clips via a blender plugin. I might take another crack at the color stabilization, it's still a problem and I've got some ideas.
I've experimented a tiny bit with seedance 2.0, and in some ways it's very impressive, but it also has a problem where animation regresses to the mean animation style, which is a crummy flash cartoon with minimal movement - which defeats the purpose. Also generating a seedance video costs $1 where generating a video locally costs $0.02. Also there's agressive content filtering. Still might be usefull for some scenes.
---
How long it takes is tricky to answer because there were different phases with different amounts of attention and effort required. First I cut the panels out and did some test runs trying to get a single animated sequence, but the results were pretty abstract so I decided to animate each frame individually. I drew keyframes for the flat chested versions, then a little bit of editing of the original panels to get clean plates, then I could use those as start and end keyframes. Then it was a matter of queuing up jobs to run over night and filtering them down to the good stuff. I generate a batch of clips, pick out the good ones, then queue up more depending on what's working and what isn't. I generated about 400 clips, sifted down to 95 good ones, then the final page uses 13. Probably 100+ gpu hours, which is a lot, but I made several mistakes and had to redo things.
Entry Level and Deep Breath both have some tight shots and overlapping panels that make it difficult to animate. I do want to get more into animated shorts, so for future projects I'm thinking about moving to more of a storyboard style where every panel is a clean 16:9 shot. I've got a little experimental 30 second short of the morale officer undressing where I drew keyframes specifically to animate with the AI, and it worked pretty well but stalled out a bit on some shots. It's got music and foley.
AI voice acting is not happening with current techniques. Sometimes I can get good results for a 10 second clip from LTX2, like maybe an instant loss or imagination teaser, but for longer stuff there's just too many variables that don't fit into a text prompt. Character consistency, speed, tone, emphasis, emotionality, pauses, there would have to be a dedicated timeline interface for these things and I haven't seen anything close to that. So we still need humans for now.
---
Organization is an ongoing problem. When I started the site I had ~200 pics and now there are > 4000. Animations like this are currently in the AI section: https://satinminions.com/AI.html I could make an "Animated Comics" subsection under animation, and probably get rid of the "ai enhanced" section which is Dain/RIFE frame interpolation. There are a couple of non-ai comic pages that have animation as well, which could fill out a subsection nicely. Though some people are touchy AI being co-mingled with traditional frame by frame and I want to be as transparent as possible. At some point AI, if used correctly, is just a tool. But what do you think?
I've experimented a tiny bit with seedance 2.0, and in some ways it's very impressive, but it also has a problem where animation regresses to the mean animation style, which is a crummy flash cartoon with minimal movement - which defeats the purpose. Also generating a seedance video costs $1 where generating a video locally costs $0.02. Also there's agressive content filtering. Still might be usefull for some scenes.
---
How long it takes is tricky to answer because there were different phases with different amounts of attention and effort required. First I cut the panels out and did some test runs trying to get a single animated sequence, but the results were pretty abstract so I decided to animate each frame individually. I drew keyframes for the flat chested versions, then a little bit of editing of the original panels to get clean plates, then I could use those as start and end keyframes. Then it was a matter of queuing up jobs to run over night and filtering them down to the good stuff. I generate a batch of clips, pick out the good ones, then queue up more depending on what's working and what isn't. I generated about 400 clips, sifted down to 95 good ones, then the final page uses 13. Probably 100+ gpu hours, which is a lot, but I made several mistakes and had to redo things.
Entry Level and Deep Breath both have some tight shots and overlapping panels that make it difficult to animate. I do want to get more into animated shorts, so for future projects I'm thinking about moving to more of a storyboard style where every panel is a clean 16:9 shot. I've got a little experimental 30 second short of the morale officer undressing where I drew keyframes specifically to animate with the AI, and it worked pretty well but stalled out a bit on some shots. It's got music and foley.
AI voice acting is not happening with current techniques. Sometimes I can get good results for a 10 second clip from LTX2, like maybe an instant loss or imagination teaser, but for longer stuff there's just too many variables that don't fit into a text prompt. Character consistency, speed, tone, emphasis, emotionality, pauses, there would have to be a dedicated timeline interface for these things and I haven't seen anything close to that. So we still need humans for now.
---
Organization is an ongoing problem. When I started the site I had ~200 pics and now there are > 4000. Animations like this are currently in the AI section: https://satinminions.com/AI.html I could make an "Animated Comics" subsection under animation, and probably get rid of the "ai enhanced" section which is Dain/RIFE frame interpolation. There are a couple of non-ai comic pages that have animation as well, which could fill out a subsection nicely. Though some people are touchy AI being co-mingled with traditional frame by frame and I want to be as transparent as possible. At some point AI, if used correctly, is just a tool. But what do you think?
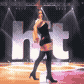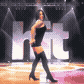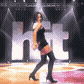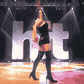
Alizee is a French pop singer who rose to popularity in the early 2000s. Her live performance of "J'en Ai Marre" on the show Hit Machine featured this dance move which made big waves on the pre-youtube internet. It also served as direct inspiration for the female night elf dance emote in World of Warcraft.
Here I have used futuristic technology to make it loop seamlessly and remove the band from the background.
Here I have used futuristic technology to make it loop seamlessly and remove the band from the background.
I will not apologize.

It's an abbreviation for a working title of a cyberpunk-esque story idea I'm toying with. I've got to name the files something and of course the golden rule is you don't abbreviate cyberpunk.

It's been a couple years, so I'm not sure. Checking my notes, the core starting idea was "guy fucks himself in a genie induced time loop". And the genie being a dumbass and swapping places with him to get out of trouble was there really early on.
The "timelines don't line up exactly" twist shows up when I start writing page numbers with dialog, but before the notes on what the title should be. So I think I had a general story outline and started blocking out pages, then figured out the details as I wrote the dialog. May or may not have sketched myself into a corner and then patched my way out of it.
The "timelines don't line up exactly" twist shows up when I start writing page numbers with dialog, but before the notes on what the title should be. So I think I had a general story outline and started blocking out pages, then figured out the details as I wrote the dialog. May or may not have sketched myself into a corner and then patched my way out of it.

This uses a video LoRa that I trained on my own artwork of the morale officer. It produces faces and shading style much more in line with my own work instead of reverting to a generic style.
I tried a few different techniques on the background, but I ended up animating it by hand.
I tried a few different techniques on the background, but I ended up animating it by hand.

A shady botnet was trying to crawl all of the /engageClick urls (used for the random thumbnails). But they're randomly generated and never end, so it ends up looping and hammering the ajax endpoint 10 times a second. Not enough to be a DDoS, but it was >100k different IP addresses from third world mobile providers and it ran the analytics to the moon which is annoying to look at. I figured out a filtering method that works for now.
This is hot on the heels of a bot successfully posting a comment here for the first time in many years (it spammed a bunch of quote escape attempts). The javascript post system filters out most bots but there's a growing trend of using headless browsers that execute javascript. This is especially stupid when kiddies dump a huge list of injection attacks into their bot, not realizing that half of them are javascript injections that then execute on their own client so they end up posting "1" thousands of times. You now get auto-banned if you post 1, so don't do that.
Speaker icon is a good idea.
This is hot on the heels of a bot successfully posting a comment here for the first time in many years (it spammed a bunch of quote escape attempts). The javascript post system filters out most bots but there's a growing trend of using headless browsers that execute javascript. This is especially stupid when kiddies dump a huge list of injection attacks into their bot, not realizing that half of them are javascript injections that then execute on their own client so they end up posting "1" thousands of times. You now get auto-banned if you post 1, so don't do that.
Speaker icon is a good idea.

Another one using my POV LoRa, was able to keep the style on this one but the motion is not quite as good. Her body is masked out with a rife fade for completely seamless movement while the background does a simple crossfade because it didn't line up.

This uses a LoRa I trained on video data, with the parent image used as the starting frame. It doesn't follow the art style of the original image, but it produces a result that isn't possible with default models, so the training worked.
Yeah on the first panel the comic has vague definition between his arm and her shoulder and the action isn't really loopable, but the other two panels came out well so I wanted to do the whole page.

Sorry about the delay, should be able to get the next 5 pages out quickly, then hopefully a more normal schedule for the second half.

Her legs are like that in the original image, perhaps a bit too splayed but, eh.
It did a pretty good job with this considering these were never meant to be keyframes. Makes me rethink what sort of shots I could get away with on a dedicated animation project.
It did a pretty good job with this considering these were never meant to be keyframes. Makes me rethink what sort of shots I could get away with on a dedicated animation project.

The character is pasted into the background. The AI model is quite GPU intensive so you don't want to waste render time on parts of the image that aren't supposed to be animated. Even if they remain static like you want, there will often be color drift and artifacts.
For this image, I cropped the character closely and rendered at 544x960. This produces clips 5 to 8 seconds long. I have some color stabilization and rife crossfade scripts to stitch multiple clips together. There was one shot where her hand went out of frame, so I ran a video outpainting pass to fill that in.
I put all the character clips together then ran auto-masking on it. Then a bit of manual touchup on the mask. I went back to the original psd file and made a clean background plate and placed the masked video of the character on top of that.
For this image, I cropped the character closely and rendered at 544x960. This produces clips 5 to 8 seconds long. I have some color stabilization and rife crossfade scripts to stitch multiple clips together. There was one shot where her hand went out of frame, so I ran a video outpainting pass to fill that in.
I put all the character clips together then ran auto-masking on it. Then a bit of manual touchup on the mask. I went back to the original psd file and made a clean background plate and placed the masked video of the character on top of that.

>don't they know about bras
Only after this girl's arrival:
https://satinminions.com/TieRemix-02.html
Only after this girl's arrival:
https://satinminions.com/TieRemix-02.html

"Uh" -- famous last words

I added the scanlines back in after.
Adding another tag to this image will fill the entire width of the page when viewed on mobile, and that causes one of the character portrait tags to be pushed down to the next line and it looks weird. I see the utility of the tag, I just can't add it instantly, I have to mess with the layout.

Sometimes a big guy pointing at you is magic enough.

I ran some tests, general animation of this scene is plausible. Toe scrunching probably won't happen without a specific lora.

I didn't think this would work but I ran some tests and it seems promising.

This lady does not have a tag because she appears entirely within this comic and is unlikely to return.
There are 10+ bit characters in the Lighter Chains universe that don't have tags that I think would be more interesting.
There are 10+ bit characters in the Lighter Chains universe that don't have tags that I think would be more interesting.

Traditionally, instant loss is a hard cut from cocky, defiant, or innocently unaware, directly into being sexually dominated.

Much sooner than 2040. There are already decent short films:
Plastic: https://youtu.be/vtPcpWvAEt0
StormtrooperVlogs: https://youtu.be/NY2nnsAplSo
You could argue it's already too easy because both of these sort of keep going after the script runs out. And there's a lot of inconsistency. Though to be fair, they were rushed to market to be first of their kind.
I think we're going to see low budget anime that does CGI characters with AI filtering pretty soon. It'll probably look better than cheap CGI.
---
For this piece I chose shots where her body looked the best and the motion matched up close enough to cross fade seamlessly (you can't render more than 5-8 seconds at a time currently).
Plastic: https://youtu.be/vtPcpWvAEt0
StormtrooperVlogs: https://youtu.be/NY2nnsAplSo
You could argue it's already too easy because both of these sort of keep going after the script runs out. And there's a lot of inconsistency. Though to be fair, they were rushed to market to be first of their kind.
I think we're going to see low budget anime that does CGI characters with AI filtering pretty soon. It'll probably look better than cheap CGI.
---
For this piece I chose shots where her body looked the best and the motion matched up close enough to cross fade seamlessly (you can't render more than 5-8 seconds at a time currently).

I added the grain effect in editing. It helps to cover up some of the color stabilization issues and I thought it suited the look of the scene. And the process is much more like film directing than traditional animation, since I run batches at night then go through the "dailies" until I collect enough good shots to stitch together into a scene.

I'm more of a Babylon 5 fan myself.

I added subnavigation chip to show all comic pages in order with the newest at the top.



If you're ok with AI. I don't want to get too side tracked from my main project which I'm a little behind on.

That sounds like a good way to get transformed yourself.

Indeed, Link gets it twice from Ganon, blissfully unaware that he's the bad guy. Zelda's warning to watch out for a pig monster wasn't specific enough.

I believe the story was she's a female in a cyberpunk setting with an augmented body, sort of a Motoko Kusanagi type.
I found the reference image and posted it.
I found the reference image and posted it.

There's a bit of artifacting from the video frame generation, then a bit more added from RIFE interpolation which sometimes has confuses small repeating patterns like fingers or toplip/bottom lip.

This is getting a bit close to pure AI slop since it's original drawing -> stable diffusion -> wan, but it's just for fun.

It's 4 cycles. I've figured out a technique for finding a good overlap point and then crossfading it with RIFE to make a seamless loop. I also made a script that will stabilize the colors on each frame, because the AI throws in a rainbow drift sometimes.

I've run a bunch of different experiments on page 4 and 5 and not had much luck. It doesn't understand the puffed out cheeks, it can't match the opacity of the smoke, it cooks the colors, it generates amateur or gross looking animation, all sorts of issues. It tends to like darker colors and more detail, but I tried running the middle panel through stable diffusion and making it a photo realistic person, and I still couldn't get good movement - something about the angle maybe.
Page 11 and 12 show some promise using sex and jiggle specific LoRAs.
Page 11 and 12 show some promise using sex and jiggle specific LoRAs.

LC started out as just forced fem slavery fun time, but it has become more complicated than that in my head. I'm definitely at the point where I have more stories than drawing power, so I don't want to promise anything then disappoint.
>Nice, which Ai you use?
WAN2.1
It seems to be the best model out there currently, runs locally on 24GB, is trainable and has LoRAs
>Did you have twitter?
I used to have a twitter bot that posted whenever a new image was released, but when Elon took over the API broke and I never bothered looking into how to fix it. If you log in (in the upper right), you can setup email notifications.
WAN2.1
It seems to be the best model out there currently, runs locally on 24GB, is trainable and has LoRAs
>Did you have twitter?
I used to have a twitter bot that posted whenever a new image was released, but when Elon took over the API broke and I never bothered looking into how to fix it. If you log in (in the upper right), you can setup email notifications.

You can just repost in the right place, unless you're making a joke about the similarities between the comics.
I took a break, just working on refining some story ideas I had. Now I'm working on a longer commission, and it'll be a little bit before I start posting pages from it.

I tried the scenes from Deep Breath and had difficulty getting good results on the transformation. The sex scenes seem to work well with the available LoRAs, so there's definitely potential.

You are in fact seeing camel toe.
This is AI generated animation using the comic as a source, with two additional images that I made specifically for the intro.
Featuring voice and sound from @_PixieWillow's sound pack.
The main music track is a short sample from "Massive Attack - Angel", extended with AI.
Featuring voice and sound from @_PixieWillow's sound pack.
The main music track is a short sample from "Massive Attack - Angel", extended with AI.
The real problem with LC1 is that there's a lot of panel breaking with characters overlapping and big gutters between the panels. So there's not a lot of places to pull a clean frame to inference on. I thought about trying a vertical video instead of horizontal but the panels kind of alternate between the two.
I made this using Wan2.1GP, a new open weight AI video model that can run locally and supports image-to-video. I provided single frames from the comic and generated 3-5 second clips and edited them together and added sound effects.
You'll just have to imagine the dialogue for now.
You'll just have to imagine the dialogue for now.
The music is AI generated using Udio.
If you intentionally logged out before posting to hide your username, you can email me: https://satinminions.com/More.html